디지털성범죄 수사와 관련된 논문입니다. 법률적인 부분은 제외하고, 기술적인 내용에 초점을 맞춰 리뷰해보겠습니다.
1. 서론
범죄 예방과 유사 범죄 방지를 위한 디지털성범죄 수사 방법 및 법률 적용은 매우 중요하다. 본 논문에서는 몰래카메라를 이용한 디지털성범죄 수사 사례를 분석하고, 2차 범죄를 예방하기 위한 디지털포렌식 조사 방법을 제안한다. 몰래카메라 영상에 음성 데이터가 존재할 경우 이를 텍스트로 변환하고 피의자 소유의 디지털 매체에 존재하는지 조사하는 방식이다.
조사 방안: 불법 촬영 영상에 음성이 포함되어 있는지 확인하고, 녹음된 음성을 추출한다. 분리한 음성을 STT(Speech-to-Text) 기술을 이용하여 대화 내용을 텍스트로 변환하고 이를 피의자가 소유한 디지털 저장매체에서 검색한다.
기대효과
- 2차 범죄에 대응하기 위한 수사 기법을 제안함으로써 유사 범죄 대응 시 실무적인 활용이 가능하다.
2. 사건 개요
<숙박업소에 미리 설치한 카메라로 투숙객을 몰래 촬영하고 해당 영상을 외부 서버 컴퓨터로 실시간 전송한 사건>
객실마다 AtHome Camera 프로그램이 설치된 "올인원 PC"를 미리 설치, "올인원 PC"를 이용해 투숙객의 성관계 장면을 촬영하고 피의자가 지정한 외부 사무실로 실시간 전송함. 뿐만 아니라 영상 속 피해자들의 대화내용을 녹음하고 엑셀 파일 등에 기록하여 협박이나 갈취와 같은 추가 범행을 준비함.
일체형 PC 분석 결과 몰래카메라 관련 프로그램 'AtHome Camera', 'AtHome Video Streamer'가 설치됨. 이 프로그램은 실시간 녹화 및 시청 기능을 제공함. 사무실 수색 결과 피의자 컴퓨터의 저장매체(SSD)에서 불법 촬영 영상(MP4) 발견. 피해자의 차량번호를 폴더 이름으로 생성하여 해당 폴더에 영상을 보관하여 저장함.
3. 이론적 배경 및 관련 연구: 몰래카메라 영상 속 음성 데이터
MP4 파일 구조는 미디어 데이터(mdat)와 미디어 데이터에 접근하기 위한 메타데이터(moov)로 구성된다. 계층 구조의 컨테이너(box)로 구성되어 있다. 기본적인 파일 구조는 ftyp, madt, moov 컨테이너로 구성되고, 실제 비디오 및 오디오 데이터는 mdat에, 이에 대한 메타데이터는 moov 하위에 저장된다. MP4 파일에 오디오 정보가 기록되어 있는지 확인하려면 moov atom의 audio track에서 stco의 Chunk offset을 찾은 후, MP4 파일의 해당 offset을 확인한다. offset 영역에 기록된 16진수 값이 존재하면 audio data가 기록된 것이고, audio track이 구성되어 있지 않거나 offset이 0x00으로 채워져 있다면 음성정보가 없는 것이다. MP4 파일은 비디오와 오디오 데이터를 분리하여 구성하는데, 이에 대한 offset 정보를 moov atom에 배열 형태로 저장한다. 실제 데이터는 mdat atom에 비디오 영역과 오디오 영역이 번갈아 가며 혼합된 형태로 저장된다.
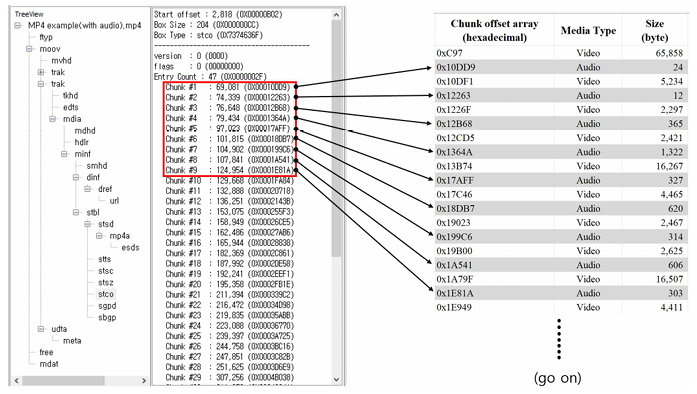
4. 제안하는 디지털포렌식 조사 방법론
4.1 몰래카메라 영상 속 음성 데이터 대상 키워드 추출
피해자들의 대화가 텍스트 형태로 존재하는지 확인하기 위해 명사형 단어를 대상 키워드로 이용할 수 있다.
1) 피해 영상의 데이터 포맷 구조를 파악하고 영상에서 음성이 저장되는 영역의 확인을 통해 음성정보가 저장되어 있는지 조사한 뒤 음성 데이터를 추출한다.
2) 추출한 음성 데이터를 텍스트로 변환하고, 변환된 텍스트 데이터 중 명사 형태소를 키워드로 추출한다.
3) 추출된 키워드가 범죄자의 저장장치에 존재하는지 검색하여 추가 범행 여부를 확인한다.
4.2 개념증명
[실험 도구 개발 및 실험 결과, 한계점]
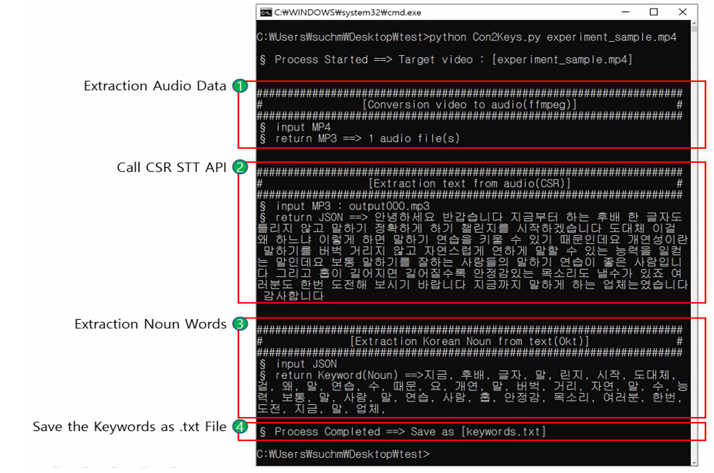
python 환경에서 ffmpeg, KoLNPy, CSR API를 이용하여 Con2Keys.py(Conversation to Keywords) POC 도구 개발
ffmpeg : 미디어 포맷 변환도구
CSR(CLOVA Speech Recognition) : 음성 데이터를 텍스트로 변환하는 API
MP4 파일에서 mdat 영역에 저장된 오디오 데이터를 추출하여 50초 단위의 MP3로 저장. HTTP 방식으로 추출한 mp3 파일을 CSR에 전송하여 JSON 형식의 STT 결과를 반환. STT 결과를 Okt 라이브러리를 이용하여 형태소분석을 통해 명사를 추출하고, 이를 txt 형식으로 저장함.
28개 단어의 정확도를 분석한 결과 정확한 한글 표기에 대한 한계가 있는 것이 확인됨. 한국어의 경우 초성, 중성, 종성이 하나의 글자를 이루고 있어 정확한 띄어쓰기와 한글 표기가 어렵다. 실무에서 활용하기 위해서는 범죄 환경과 유사한 상황에서 생성된 음성 데이터에 대한 딥러닝 학습이 필요하고, 성능 측정을 위한 평가방법론이 함께 적용되어야 한다.
5. 결론
디지털성범죄 예방 및 유사 범죄 방지를 위해 불법으로 영상을 촬영하고 유포하는 행위 외에 피해자의 내밀한 대화내용을 악용한 행위에 대한 통신비밀보호법의 추가 수사가 필요하다. 즉, 영상에 음성이 포함되어 있는지 디지털포렌식 분석을 통한 확인과, 영상 속 비밀대화를 악용한 2차 피해가 있었는지 추가 조사가 필요하다.
논문의 주된 요점은 불법 촬영 영상 소지, 유포 뿐만 아니라 해당 영상 속 음성대화를 악용한 2차 범죄를 방지하기 위해 추가 수사가 필요하다는 내용입니다. 다만 실제 수사과정에서 수사관이 대량의 동영상 파일을 일일이 확인하는 것이 어렵기 때문에, 동영상 내의 음성대화 키워드를 자동으로 추출해주는 도구가 좀 더 개선된다면 추가 수사에 도움이 될 것 같네요.
'Digital Forensics > 논문리뷰' 카테고리의 다른 글
| [논문리뷰] 메모리 포렌식 관점에서의 모바일 브라우저 사생활 모드 분석 (0) | 2024.12.12 |
|---|